Spectral analysis of LOBO data in Elkhorn Slough - Part 2
Contents
3. Spectral analysis of LOBO data in Elkhorn Slough - Part 2#
This notebook continues a demonstration of spectral analysis using water level and nitrate data from Elkhorn Slough.
For the basics of computing the Fast Fourier Transform and displaying the power spectrum as a periodogram, see Part 1. In Part 2, we focus on improving the estimate of power spectral density through pre-whitening, smoothing and windowing. These techniques address the following issues in computing the raw periodogram from the FFT of the original data.
noise (random error)
bias (systematic error)
These errors arise due to the finiteness of data, both the finite length of the data set (rather than infinite) and the finite intervals between samples (rather than infinitessimal). As explained by J.W. Tukey,
“The finiteness of real data forces us to face three things in any attempt to study the frequencies in something given by numbers:
aliasing,
the need for sensible data windows, and
the inevitability of frequency leakage.”
The analysis that follows gives examples of steps that can be taken to minimize these errors in practical spectral analysis.
3.1. Loading data#
These steps are identical to Part 1.
import numpy as np
import matplotlib.pyplot as plt
filename = 'data/MBARI_LOBO/L01SURF_subset.txt'
data = np.genfromtxt(filename,delimiter=',',skip_header=3)
# replace missing data with NaN
flagi = np.where(data>1E100)
data[flagi] = np.nan
time = data[:,1] # days since 1/1/1900
nitrate = data[:,2]
waterdep = data[:,3]
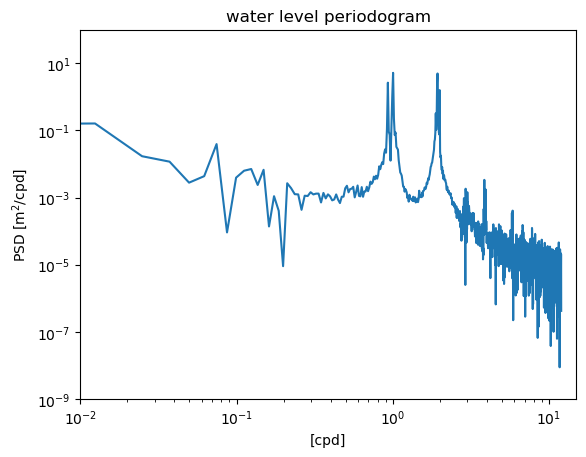
3.2. Raw periodogram#
As we have already seen in Part 1, the scipy.signal library contains a function for computing the raw periodogram. The inputs are the 1) values of the time series, and 2) the sampling frequency.
from scipy.signal import periodogram
fp,Sp = periodogram(waterdep,fs=24.)
plt.figure()
plt.loglog(fp,Sp)
plt.ylim([1e-9,1e2])
plt.xlim([1e-2,1.5e1])
plt.xlabel('[cpd]')
plt.ylabel('PSD [m$^2$/cpd]')
plt.title('water level periodogram')
Text(0.5, 1.0, 'water level periodogram')
3.3. Modified periodograms#
In order to improve on the raw periodogram, we use another function in the scipy.signal module, which uses Welch’s method. This function allows us to improve on the raw periodogram in the following ways:
pre-whitening the data by removing a linear trend
smooth the estimate by averaging multiple spectral estimates
applying a window to the data (weighting certain data points more than others)
Welch’s method averages the estimate by dividing the time series in to shorter, overlapping segments and avergaing the resulting spectral estimates. However, the averaging process smooths the spectrum, reducing noise, and increases the number of degrees of freedom. The drawbacks of this method (and any other method of averaging spectral estimates) are effectively reduces the length of the time series being analyzed, and it may blur narrow-banded peaks in the spectrum.
Like all spectral methods, Welch’s method is most effective when used in combination with a window that weights the middle of the segments more than the edges. This reduces the noise that is introduced into the spectrum that occurs at the “jump” in the time series when it is assumed to be periodic and the end wraps back around to the beginning.
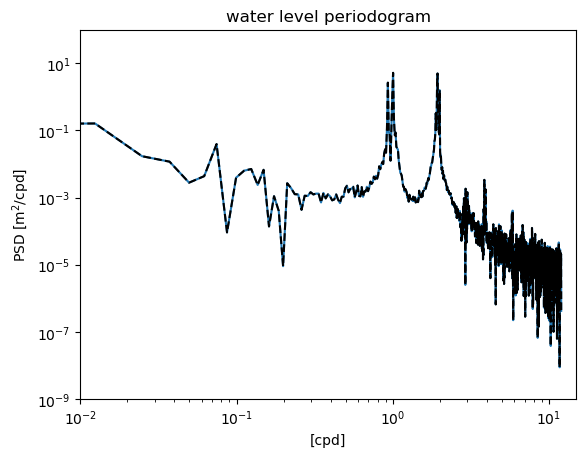
Reproducing the raw periodogram#
We start by using scipy.signal.welch function to reproduce what we have already done. The raw periodogram can be thought as using only one segment (which has the length of the original time series, \(N\)) and a “boxcar” (or rectangular) window that weights all data points equally. Using these options in the welch function gives the exact same result as the original periodogram.
from scipy.signal import welch
N = len(waterdep)
f2,S2 = welch(waterdep,fs=24.,nperseg=N,window='boxcar')
plt.figure()
plt.loglog(fp,Sp)
plt.loglog(f2,S2,'k--')
plt.ylim([1e-9,1e2])
plt.xlim([1e-2,1.5e1])
plt.xlabel('[cpd]')
plt.ylabel('PSD [m$^2$/cpd]')
plt.title('water level periodogram')
Text(0.5, 1.0, 'water level periodogram')
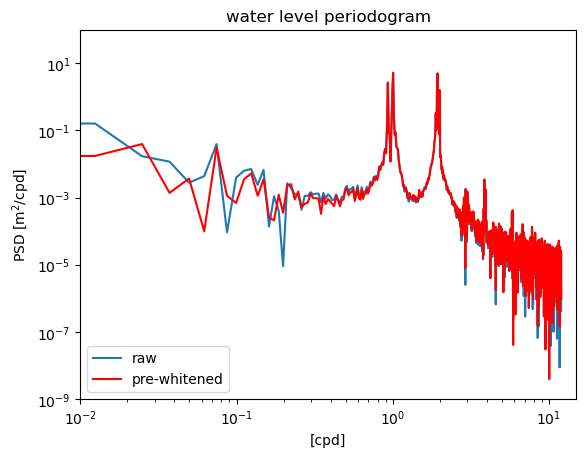
Pre-whitening#
If the data contains a significant trend, this can exacerbate the noise introduced by having different values near the end and beginning of the data set. Detrending the data before computing the spectrum can help. In this case, the water level spectrum does not have a very large trend. We obtain an estimate that is different, but not drastically so.
f3,S3 = welch(waterdep,fs=24.,nperseg=N,window='boxcar',detrend='linear')
plt.figure()
plt.loglog(fp,Sp)
plt.loglog(f3,S3,'r')
plt.ylim([1e-9,1e2])
plt.xlim([1e-2,1.5e1])
plt.xlabel('[cpd]')
plt.ylabel('PSD [m$^2$/cpd]')
plt.title('water level periodogram')
plt.legend(['raw','pre-whitened'],loc='lower left')
<matplotlib.legend.Legend at 0x12fd4b2e0>
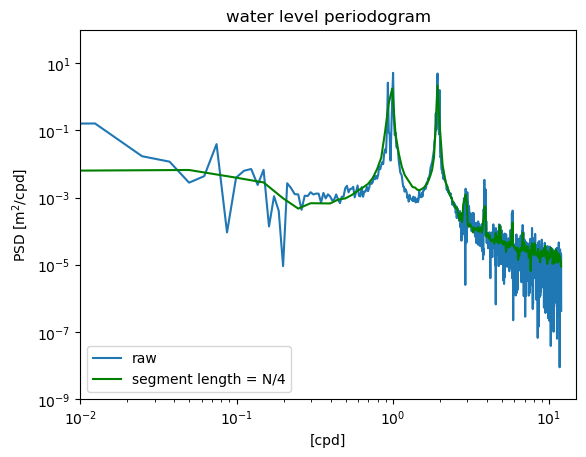
Averaging segments#
In this example, the time series is divided into segments of length \(N/4\), and the spectral estimates derived from these shorter segments are averaged. This implements Welch’s method, and results in a smoother spectrum with less noise (i.e. reduced random error).
However, this method also blurs together the two dirnal peaks near the 1 cpd frequency, so it could be argued that important information is lost by over-smoothing.
f4,S4 = welch(waterdep,fs=24.,nperseg=N/4,window='boxcar',detrend='linear')
plt.figure()
plt.loglog(fp,Sp)
plt.loglog(f4,S4,'g')
plt.ylim([1e-9,1e2])
plt.xlim([1e-2,1.5e1])
plt.xlabel('[cpd]')
plt.ylabel('PSD [m$^2$/cpd]')
plt.title('water level periodogram')
plt.legend(['raw','segment length = N/4'],loc='lower left')
<matplotlib.legend.Legend at 0x175ebed10>
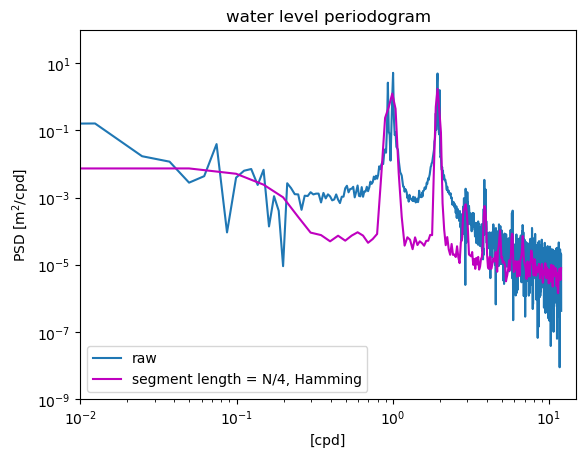
Using a sensible window#
All of the examples up to this point have used a rectangular window that weights all points in the time series equally. In contrast, a Hamming window weights the points in the middle of the time series more than the points on the edges near the beginning and end. This reduces the spurious energy that is introduced into the spectrum at the discontinuits where the end of the time series wraps around to the beginning (remember that the time series is effectively treated as a periodic function in Fourier analysis).
Applying the window not only smooths the data, reducing noise (random error), but also reduces the biased overestimate that occurs when all data points are weighted equally (systematic error). The background PSD is reduced, and this reveals much more clearly the peaks at the harmonics of the diurnal 1 cpd frequency, which occur due to the dynamics of friction tidal flow in shallow water.
f5,S5 = welch(waterdep,fs=24.,nperseg=N/4,window='hamming',detrend='linear')
plt.figure()
plt.loglog(fp,Sp)
plt.loglog(f5,S5,'m')
plt.ylim([1e-9,1e2])
plt.xlim([1e-2,1.5e1])
plt.xlabel('[cpd]')
plt.ylabel('PSD [m$^2$/cpd]')
plt.title('water level periodogram')
plt.legend(['raw','segment length = N/4, Hamming'],loc='lower left')
<matplotlib.legend.Legend at 0x176141b70>
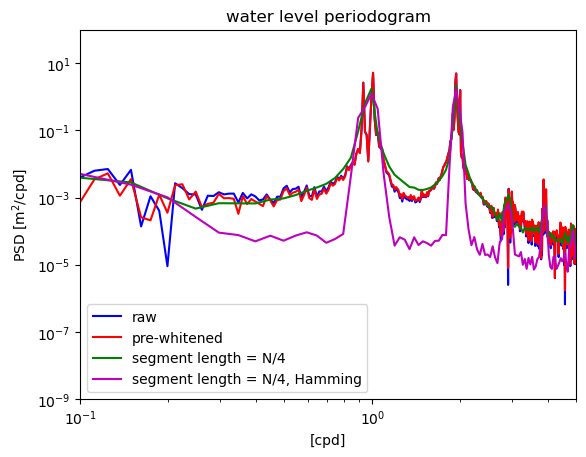
Comparing spectral estimates#
The differences between different windowing and averaging methods can be seen more clearly by zooming in to the dominant peaks in the time series.
plt.figure()
plt.loglog(fp,Sp,'b')
plt.loglog(f3,S3,'r')
plt.loglog(f4,S4,'g')
plt.loglog(f5,S5,'m')
plt.ylim([1e-9,1e2])
plt.xlim([1e-1,5e0])
plt.xlabel('[cpd]')
plt.ylabel('PSD [m$^2$/cpd]')
plt.title('water level periodogram')
plt.legend(['raw','pre-whitened','segment length = N/4','segment length = N/4, Hamming','segment length = N/2, Hamming'],loc='lower left')
<matplotlib.legend.Legend at 0x12fd192a0>
3.4. Confidence intervals and degrees of freedom#
The confidence intervals for a spectral estimate are most conviently expressed in terms of their logarithms,
where \(S(f)\) is the “true” spectrum of signal and \(\tilde{S}(f)\) is the estimate obtained from finite data. \(\nu\) is the effective degrees of freedom, which depends on the averaging and windowing methods. The estimates at each frequency band in the raw periodogram have \(\nu\) = 2 degrees of freedom (no averaging or windowing). If two independent segments are averaged (segment length = \(N/2\)), the estimate has \(\nu\) = 4 degrees of freedom, etc. Windowing the data also increases the degrees of freedom by a factor that depends on the specific window being used.
Type of window |
Increase \(\nu\) by factor |
|---|---|
Boxcar |
None |
Bartlett |
3 |
Daniell |
2 |
Parzen |
3.708614 |
Hanning |
(8/3) |
Hamming |
2.5164 |
For example, averaging segments with length \(N/2\) and applying a Hanning window results in a total of \(4 \times 8/3 = 32/3\) degrees of freedom.
These confidence intervals can be throught of a vertical region surrounding each spectral estimate. If differences between the log-transformed PSD estimates at two different frequencies are smaller than the width of these intervals, than they are not statistically significant.
Recall that the difference between log-transformed values can be thought of as a ratio of untransformed values. The advantage of expressing the confidence intervals on a logarithmic scale is that a single interval applies to all frequencies and can be expressed as a single vertical bar on a log-log plot.
See Emery and Thomson, Section 5.6.8, for further in-depth discussion of this topic.
3.5. Exercises#
Plot a “best” esimate of the power spectrum for nitrate
Plot 95% confidence interval on log scale
4. Low pass filtering data#
This section compares two filtering methods.
The running average (or “boxcar” filter)
cosine-Lanczos filter
Both methods use the same general procedure of convolution. The original time series is convolved with a set of weights in order to obtain a smoothed, low-pass filtered time series.
The running average is intuitive but not recommended. The cosine-Lanczos filter is commonly used in oceanography. It requires more weights, but is more effective at suppressing high-frequency variance and retaining low-frequency variance.
Emery and Thomson describe the cosine-Lanczos filter in detail, as well as a number of other filtering methods.
from scipy import signal
4.1. Running average/boxcar#
The running average is equivalent to convolution with a set of equal weights. In this example we average over a time period of 40 hours in order to average out tidal and other high-frequency fluctuations. The signal.boxcar function generates the set of 40 weights for this example.
weights = signal.boxcar(40)
weights
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1.])
It is important that the sum of the weights equals 1, so the weights are normalized.
weights_norm = weights/sum(weights)
np.sum(weights_norm)
1.0
plt.figure()
plt.plot(weights_norm,'.')
[<matplotlib.lines.Line2D at 0x1763e6140>]
4.2. cosine-Lanczos#
The scipy signal processing package contains a number of pre-designed windows. Custom filters can also be generated with the signal.firwin function (FIR is short for “finite impulse response”).
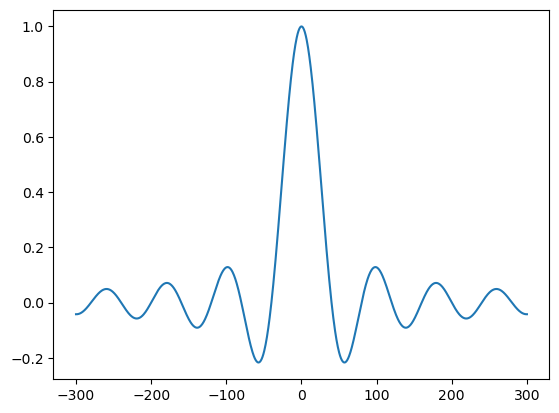
The ideal set of weights is a sinc function,
In this function, the value of \(f_c\) determines the “cutoff frequency”. In an ideal filter, variance at all frequencies lower than \(f_c\) would be retained and all variance at frequencies higher than \(f_c\) would be retained.
x = np.linspace(-300,300,1000)
f = 1/40
plt.figure()
plt.plot(x,np.sinc(f*x))
[<matplotlib.lines.Line2D at 0x1774adfc0>]
However, the sinc function is not practical because it would require an infinite set of weights. We could truncate it, but this would lead to discontinuities at the edges. FIR filters apply a window to this function, keeping the middle the same, but tapering it off on the edges.
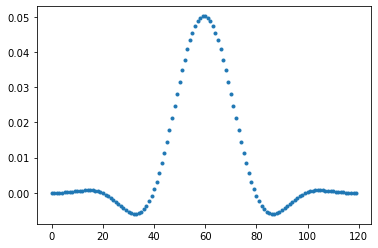
Here, we generate a set of 120 weights, with cutoff frequency \(f_c\) of 1/40 hours. A Hanning window is used to taper of the set of weights so that they are zero at the edges. The weights are automatically normalized so that the sum is equal to 1.
lancz_weights = signal.firwin(120,1/40,fs=1,window='hanning')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
File ~/opt/miniconda3/envs/data-book/lib/python3.10/site-packages/scipy/signal/windows/_windows.py:2214, in get_window(window, Nx, fftbins)
2213 try:
-> 2214 beta = float(window)
2215 except (TypeError, ValueError) as e:
ValueError: could not convert string to float: 'hanning'
During handling of the above exception, another exception occurred:
KeyError Traceback (most recent call last)
File ~/opt/miniconda3/envs/data-book/lib/python3.10/site-packages/scipy/signal/windows/_windows.py:2232, in get_window(window, Nx, fftbins)
2231 try:
-> 2232 winfunc = _win_equiv[winstr]
2233 except KeyError as e:
KeyError: 'hanning'
The above exception was the direct cause of the following exception:
ValueError Traceback (most recent call last)
Input In [13], in <cell line: 1>()
----> 1 lancz_weights = signal.firwin(120,1/40,fs=1,window='hanning')
File ~/opt/miniconda3/envs/data-book/lib/python3.10/site-packages/scipy/signal/_fir_filter_design.py:463, in firwin(numtaps, cutoff, width, window, pass_zero, scale, nyq, fs)
461 # Get and apply the window function.
462 from .windows import get_window
--> 463 win = get_window(window, numtaps, fftbins=False)
464 h *= win
466 # Now handle scaling if desired.
File ~/opt/miniconda3/envs/data-book/lib/python3.10/site-packages/scipy/signal/windows/_windows.py:2234, in get_window(window, Nx, fftbins)
2232 winfunc = _win_equiv[winstr]
2233 except KeyError as e:
-> 2234 raise ValueError("Unknown window type.") from e
2236 if winfunc is dpss:
2237 params = (Nx,) + args + (None,)
ValueError: Unknown window type.
np.sum(lancz_weights)
1.0
plt.figure()
plt.plot(lancz_weights,'.')
[<matplotlib.lines.Line2D at 0x11497a760>]
4.3. Application and comparison#
For both sets of weights, the smoothed time series is obtained through covolution of the weights with the original time series.
nitrate_avg =np.convolve(nitrate,weights_norm,'same')
nitrate_filt =np.convolve(nitrate,lancz_weights,'same')
plt.figure(figsize = (10,5))
plt.plot(time,nitrate)
plt.plot(time,nitrate_avg)
plt.plot(time,nitrate_filt)
plt.legend(['unfiltered','boxcar','cosine-lanczos'])
plt.ylabel('nitrate [$\mu$M]')
Text(0, 0.5, 'nitrate [$\\mu$M]')
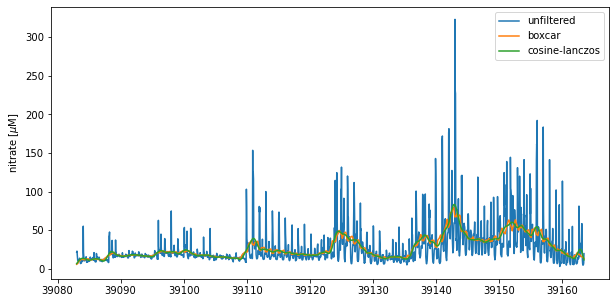
Both methods dampen the tidal signal in this time series. However, the cosine-Lanczos is more effective and generates a smoother time series.