Modeling, sampling, confidence intervals
Contents
3. Modeling, sampling, confidence intervals#
3.1. Recommended reading#
http://statsthinking21.org/index.html Chapters 7,8
Glover, Jenkins and Doney: Section 2.7 - The central limit theorem
Emery and Thomson: Confidence intervals, 3.8.1, 3.8.2 – Confidence interval for mean
3.2. Probability Density Function (PDF) review with example data set#
Probability density function#
\(N\) = 10623 anchovy weight samples
\(\Delta x\) = 5 g
Review: How to calculate PDF from counts, N and \(\Delta x\)?
With the histogram we have the following information: counts, bin width ( \(\Delta x\) = 5g), \(N\) (samples).
PDF = fraction/\(\Delta x\) = counts/(\(N \Delta x\))
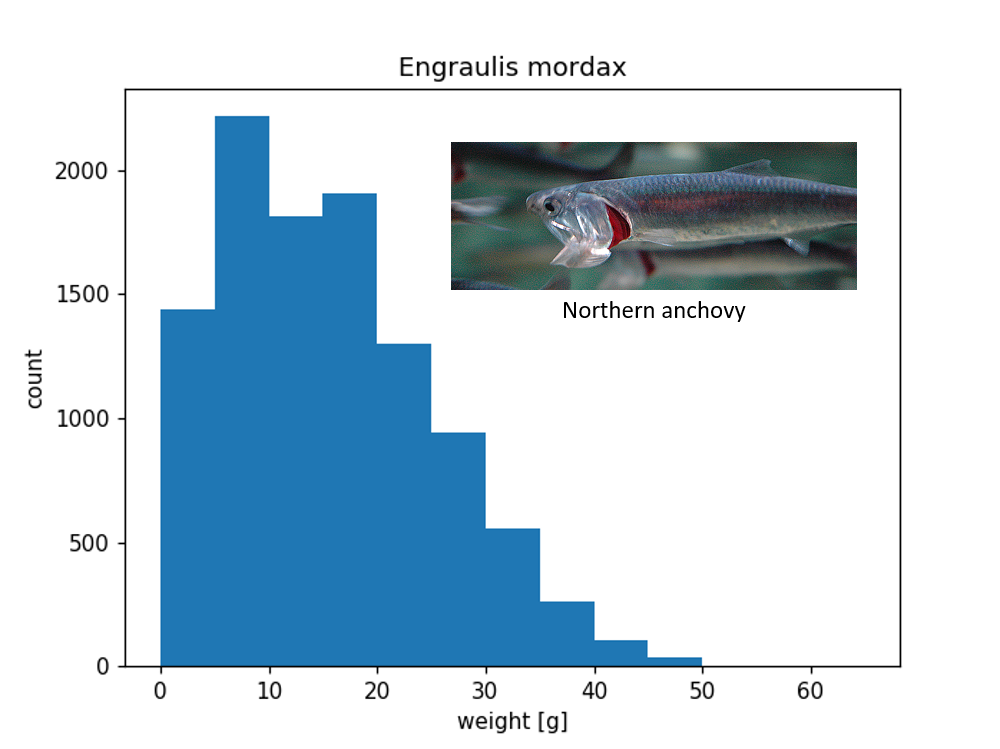
NOAA SWFSC - Trawl Life History Specimen Data#
fishery independent trawl surveys of coastal pelagic species
Surveys: 2003-2019
Subsampled data set#
If we think of the above PDF as repesenting the total poulation of Engraulis mordax in the whole ocean, then you can think of the subsample as a result you might get if you just went out and trawled for one day.
Click the button to generate a random set of \(N\) subsamples from the larger dataset.
<function __main__.plot_subsampled_weight_histogram(species_name, N=100)>
\(N\) = 100 anchovy weight samples
What are the key differences, similarities of this distribution, compared with all 10623 samples?
differences: a pdf of smaller sample sizes are noiser, less smooth. May see more variability from one bin to the next.
similarities: theoretical distribution resembles poisson distribution (skewed data set with a longer tail), scale of y-axis (normalized by the bin width so magnitudes of different data sets are comparable)
Statistical modeling#
What is a model?#
Physical models (e.g., of a building, of Monterey Bay, of a cell or a molecule) represent something on a different scale to make it easier to understand. They convey the essence of something without having to worry about all the details. A statistical model is same basic idea as a physical model, we want to convey the essence of the dataset without having to use an entire dataset
Basic structure of a statistical model#
A statistical model is based off data. Error is an inherent part of of any model prediction. One of the key goals in evaluating a model is to quantify that error.
data = model + error
\(x_i = \hat{x}_i + \epsilon_i\)
where \(x_i\) is one data point, \(\hat{x}_i\) is the corresponding model predition, and \(\epsilon_i\) is the difference between them.
Example data set: simplest model#
The simplest possible model is a single value#
Mode = 5 g
Mean = 15.326 g
Median = 14 g
In this case the mean is much bigger than the mode is about 15 grams (data is skewed). A median describes the central value, or 50th percentile in the data set.
If we use the mode as the model, we can write it as: \(\hat{weight_i}\) = 5 g
The \(\hat{}\) denotes a value predicted by the model
The subscript \(_i\) denotes one data point with the model value, a generic observation. For example, if we specify \(i=1\), it could mean the first row in a spreadsheet.
We can describe the error based on the model structure: \(error_i = weight_i - \hat{weight_i}\)
where \(weight_i\) is an observation, or data point, and \(\hat{weight_i}\) is the corresponding model prediction. Each observation has a model prediction and an error associated with it.
In the example, if we have 10623 data points, then a model will have 10263 errors.
Example data set: mode as a model#
/var/folders/z7/lmyk7sz94177j166ck0x63h80000gr/T/ipykernel_61404/2487761942.py:7: FutureWarning: Unlike other reduction functions (e.g. `skew`, `kurtosis`), the default behavior of `mode` typically preserves the axis it acts along. In SciPy 1.11.0, this behavior will change: the default value of `keepdims` will become False, the `axis` over which the statistic is taken will be eliminated, and the value None will no longer be accepted. Set `keepdims` to True or False to avoid this warning.
plt.plot([mode(weight)[0], mode(weight)[0]],[yl[0], yl[1]], 'r--', lw=2)
<Figure size 640x480 with 0 Axes>
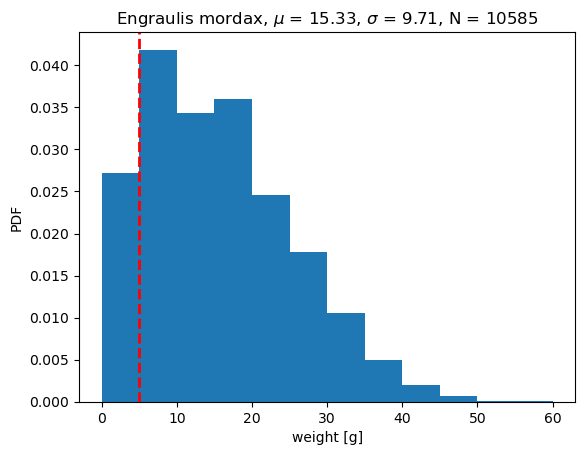
With this model, each model prediction has a constant value of 5 g, that is,
\(\hat{x}_i\) = 5 g.
The average error, \(\bar{\epsilon_i} = \overline{(x_i - \hat{x}_i)}\), when using mode as model is 10.326 g. In other words the positive errors dominate the average error.
If we use the mean as a model, would you expect the average error increase or decrease?
Example data set: mean as a model#
<Figure size 640x480 with 0 Axes>
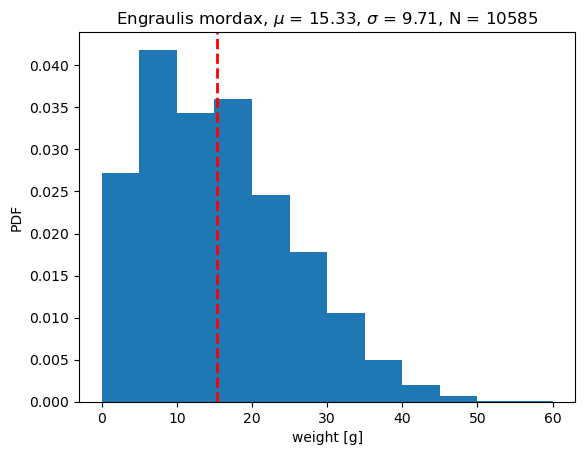
If we use the mean as a model, \(\hat{x_i} = \bar{x_i}\)
The average error when using mean as a model is 0.0g. In this case, the negative errors cancel out the positive errors. In this case, the mean error does not do a good job of describing the distribution of errors. In fact, this metric is a measure of bias but does not say anything about the random errors (precision) of the model.
What other metrics can we use to quantify model error?#
Some ways of quantifying the error:
We can describe the mean error (average error) as:
\(ME = \frac{1}{N} \sum_{i=1}^N (x_i - \hat{x_i})\)
If our model (\(\hat{x_i}\)) is the mean of the dataset (\(\bar{x_i}\)), then the ME = 0 and the model is unbiased.
Sum of Squared Errors#
\(SSE = \sum_{i=1}^N (x_i - \hat{x_i})^2\)
(This treats the positive and negative values equally)
Mean Squared Error#
\(MSE = \frac{1}{N} SSE\)
Root Mean Square Error#
\(RMSE = \sqrt{MSE}\)
The units for RMSE will make it easier to understand the error mismatch. This is a summary of all the errors in the dataset by penalizing all errors in the dataset equally. For our two models examined so far, where the model is only a constant value, the RMSE can by summarized as:
RMSE(mean) = 9.71 grams
RMSE(mode) = 14.18 grams
The mean is the single value that minimizes RMSE#
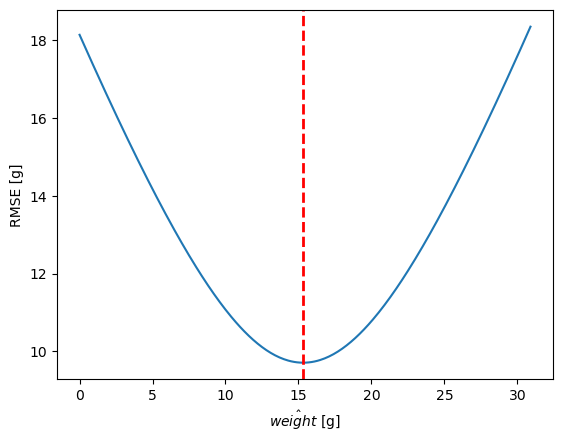
This plot is showing the RMSE as a function of the model value.
This plot is an example of what is called a cost function. We have a model parameter on the x-axis and an error, or “cost” on the y-axis. In modeling we are often interested in the parameter that minimizes the cost function.
The vertical dashed line shows the mean value. Out of all possible models defined by a single parameter, the mean is the one the minimizes the RMSE and would be considered most optimal.
A simple model with two parameters: linear model#
Let’s say that we want to model fish weight as a function of length for this species. This might be useful in a case where length estimates are common, but weight estimates are more labor-inetensive. Or maybe there is interest in comparine length-weight relationships for different species.
import xarray as xr
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
import matplotlib.pyplot as plt
# load dataset and convert to Pandas dataframe
ds = xr.open_dataset('data/trawl_swfsc/FRDCPSTrawlLHSpecimen_8b4e_b841_9c81.nc')
df = ds.to_dataframe()
dfsub = df.loc[(df['scientific_name'] == 'Engraulis mordax') &
(ds['standard_length'].values < 1e8)]
# linear fit with statsmodels package
results = smf.ols('weight ~ 1 + standard_length', dfsub).fit()
# RMSE
err = dfsub['weight']-(results.params[0]+results.params[1]*dfsub['standard_length'])
rmse = np.sqrt(np.mean(err**2))
# plot linear model
plt.figure()
plt.plot(dfsub['standard_length'],dfsub['weight'],'.')
plt.plot(dfsub['standard_length'],
results.params[0]+results.params[1]*dfsub['standard_length'],
'-')
plt.xlabel('standard length [mm]')
plt.ylabel('weight [g]')
plt.title('Engraulis mordax, RMSE = '+str(np.round(rmse,2))+ ' g');
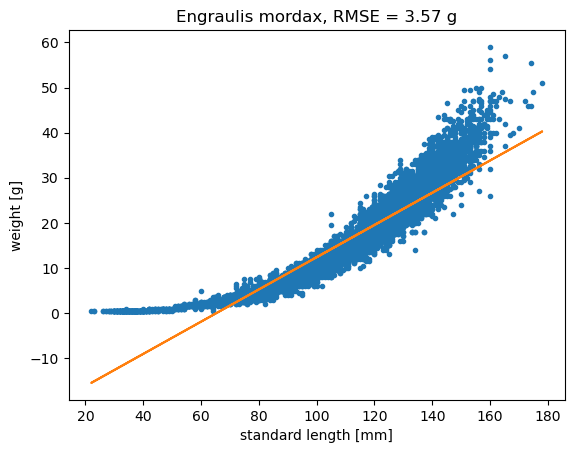
The linear model has RMSE = 3.57 g
Looking at the data, it looks like a linear model only works for part of the data. It tends to be biased low at the smallest and largest length values. If we were going to use this linear model, our equation would be:
\(\hat{weight_i} = constant + a * length_i\)
The \(\hat{}\) symbol indicates \(\hat{weight_i}\) is a model
Here the \(constant\) is the intercept and \(a\) is the slope.
The intercept and slope are the model parameters. You can think of the error \(\epsilon_i\) for each data point as being the vertical distance between the data point and the model, \(x_i - \hat{x}_i\).
Example data set: quadratic model#
resultsq = smf.ols('weight ~ 1 + standard_length + I(standard_length**2)', dfsub).fit()
errq = dfsub['weight']-(resultsq.params[0]+
resultsq.params[1]*dfsub['standard_length']+
resultsq.params[2]*dfsub['standard_length']**2)
rmseq = np.sqrt(np.mean(errq**2))
plt.figure()
plt.plot(dfsub['standard_length'],dfsub['weight'],'.')
plt.plot(dfsub['standard_length'],
resultsq.params[0]+
resultsq.params[1]*dfsub['standard_length']+
resultsq.params[2]*dfsub['standard_length']**2,
'.')
plt.xlabel('standard length [mm]')
plt.ylabel('weight [g]')
plt.title('Engraulis mordax, RMSE = '+str(np.round(rmseq,2))+ ' g');
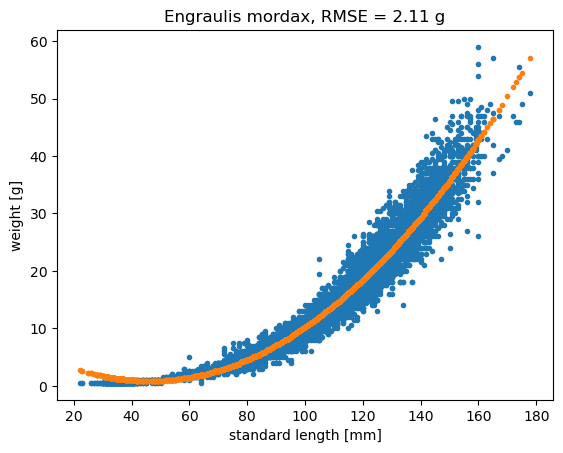
The quadratic model has RMSE = 2.11 g.
\(\hat{weight_i} = constant + a * length_i + b * length_i^2\)
The constant, a, and b are model parameters that describe the structure or the shape of the model. We can find the model that minimizes the RMSE. This looks like it is doing better than a linear model, but the model indicates that their weight decreases as they get bigger for smaller fish. It still has some systematic errors where there is some bias.
Example data set: data transformation#
plt.figure()
plt.plot(np.log(dfsub['standard_length']),
np.log(dfsub['weight']),'.')
plt.xlabel('ln(standard length [mm])')
plt.ylabel('ln(weight [g])')
plt.title('Engraulis mordax');
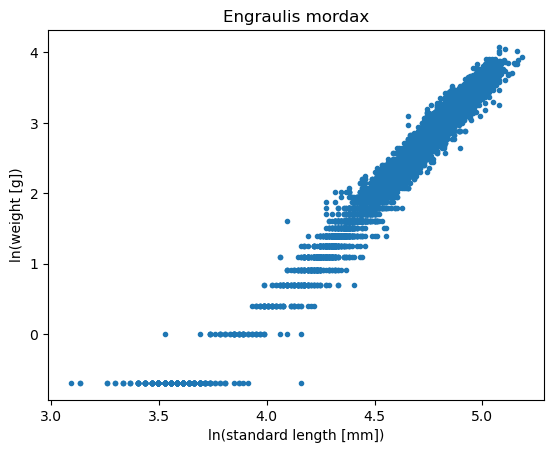
This is the same data transformed to a logarithmic scale, and now it appears that a linear model may be appropriate. Now, we are not minimizing the RMSE, you are minimizing the logarthmic RMSE.
What makes a model good?#
good fit
minimizes error
represents actual scenario of the data
is not overcomplicated
Modeling another species - Overfitting#
Overfitting occurs when a model is overcomplicated and not representative of the actual scenario. If we add more parameters by adding more terms to the polynomial model equation, we may get an unrealistic model with a low RMSE. Symptoms of overfitting include large swings in model curves where no data points exist.
If another datapoint is added without readjusting the model (for example, if a Icichthys lockingtoni specimen with 150 mm length were caught), the RMSE will likely be large.
Datasets with large sample sizes are still prone to overfitting. Even with many data points, a model for Engraulis mordax with many coefficients is overly sensitive to the extreme data values.
interact(plot_length_vs_weight_data_with_fit,
species_name = ['Icichthys lockingtoni', 'Engraulis mordax'],
N=widgets.IntSlider(min=0, max=10, step=1, value=7));
Sampling#
Statistical inference: One of the foundational ideas in statistics is that we can make inferences about an entire population based on a relatively small sample of individuals from that population.
Goal of sampling: determine the value of a statistic for an entire population of interest, using just a small subset of the population.
The way in which we select the sample is critical to ensuring that the sample is representative of the entire population.
Adapted from: http://statsthinking21.org/sampling.html
Back to the anchovy data example: distribution of means#
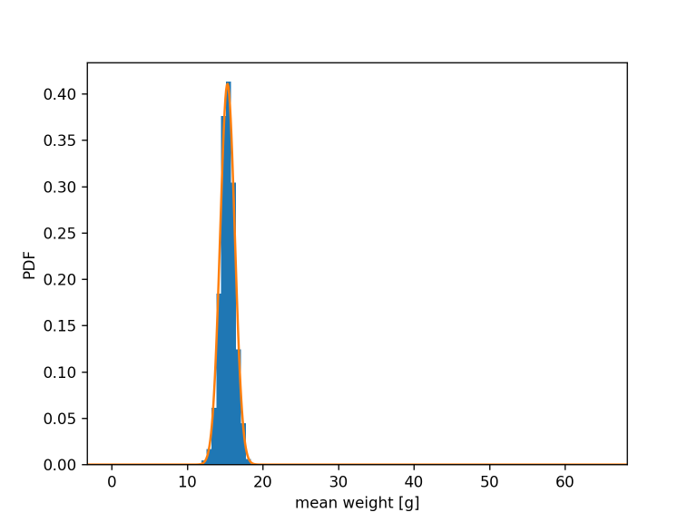
Blue bars: distribution of 1000 different sample means (\(\bar{x}\)), with N = 100 samples each
Mean of \(\bar{x}\) = 15.346 g Std. dev. of \(\bar{x}\) = 0.933 g
Orange curve: normal distribution
\(\mu\) = 15.327 g (mean of full data set)
\(\frac{\sigma}{\sqrt{N}}\) = 0.971 g (std. dev. of full data set / √100)
Anchovy data: distribution of means (zoomed in)#
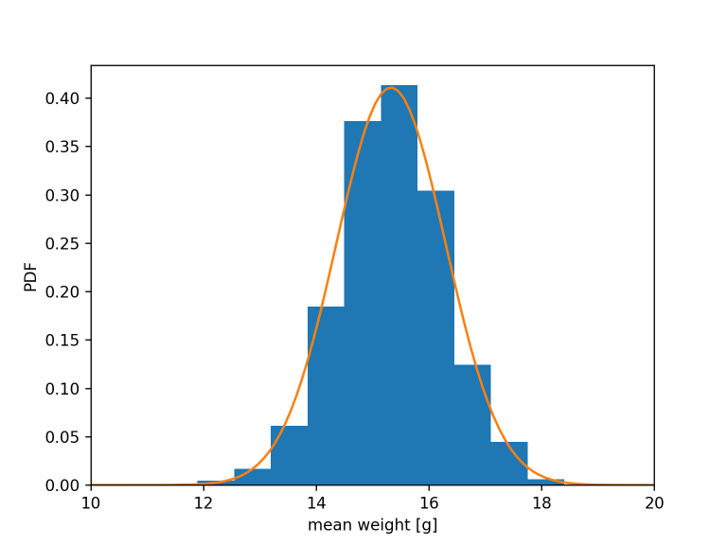
Blue bars: distribution of 106 different sample means (\(\bar{x}\)), with N = 100 samples each#
Mean of \(\bar{x}\) = 15.358 g Std. dev. of \(\bar{x}\) = 0.822 g
Orange curve: normal distribution#
\(\mu{}\) = 15.327 g (mean of full data set)
\(\frac{\sigma}{\sqrt{N}}\) = 0.971 g (std. dev. of full data set / √100)
This is a consequence of the central limit theorem.
interact(plot_distribution_of_subsampled_weight_means,
species_name = fixed(species_name),
N = widgets.IntSlider(min=1, max=100, step=1, value=3),
n_subsamples = widgets.IntSlider(min=10, max=1000, step=20, value=1000))
<function __main__.plot_distribution_of_subsampled_weight_means(species_name, N, n_subsamples)>
3.3. The Central Limit Theorem#
The central limit theorem states that no matter what the probability distribution of parent population is, the mean of the means drawn from the same population is normally distributed for large sample sizes. As \(N\) approaches infinity,
mean \((\bar{x}) \rightarrow \mu\) (the mean of the sample means approaches the true mean)
std \((\bar{x}) \rightarrow \frac{\sigma}{\sqrt{N}}\) (the standard deviation of the sample means approaches the true standard error)
The important consequence of this theorem is that if you collect enough samples, the sample mean will always provide an unbiased estimate of the true mean and you can calculate confidence intervals with the formulas above.
However, if you have too few samples, the sample mean will provide a biased estimate.
Some examples of situation where the central limit theorem is applied:
Radiochemists study discrete decay events, which follow a Poisson distribution. A few samples will give a biased estimate of the mean rate of radioactive decay. If enough samples are collected, the sample mean and 95% confidence intervals can be calculated using the formulas described above.
Physical oceanographers routinely take advantage of the central limit theorem when using observations of pressure or velocity measurements to study processes with time scales much longer than individual waves. The probability distribution of a wavy sea surface is not normal at all, but by collecting many samples (a.k.a. an “ensemble”) over a period of ~10-20 minutes the waves are effectively “averaged out” and one can be reasonably confident in the mean of that ensemble.
When sampling a noisy environment and ensemble averaging, oceanographers must be careful to choose an ensemble that is long enough to collect enough samples, but not so long that the statistics are changing significantly over longer time scales. If statistics are robust regardless, of the sampling duration, the process is said to be stationary.
*Adapted from: http://statsthinking21.org/sampling.html
Central limit theorem (in other words)#
The distribution of an average tends to be Normal, even when the distribution from which the average is computed is decidedly non-Normal.
http://www.statisticalengineering.com/central_limit_theorem.htm
The amazing and counter-intuitive thing about the central limit theorem is that no matter what the shape of the original distribution, the sampling distribution of the mean approaches a normal distribution. Furthermore, for most distributions, a normal distribution is approached very quickly as N increases.
Central limit theorem - applications#
The weight distribution of Engraulis mordax is skewed. However, if we have hundreds of samples, the 95% confidence interval for the mean can still be estimated as
\(\bar{x}\) ±1.96 \(\frac{s}{\sqrt{N}}\)
With very few samples, the mean would not only be uncertain, but also biased.
The z Distribution#
According to the central limit theorem, sample means (\(\bar{x}\)) are normally distributed for large N.
This gives you data that is standardized in a way that if we take z-scores of the sample means (\(\bar{x}\)), 95% of them should fall in the range:
-1.96 < z < 1.96
This is the basis for forming 95% confidence intervals
Confidence intervals for the mean#
For large sample size \(N\):
\(CI_{95\%} = \bar{x} \pm 1.96 \times SE\), where SE is the standard error \(\frac{S}{\sqrt{N}}\)
With large enough \(N\), the 95% confidence interval will contain the true population mean 95% of the time. Here 1.96 is a critical z-score. In theory, if a population is normally distributed then 95% of the z-scores will be between -1.96 and 1.96.
This equation is only valid for large samples sizes. For small sample sizes, we use a t-distribution instead of z-distribution (covered later).
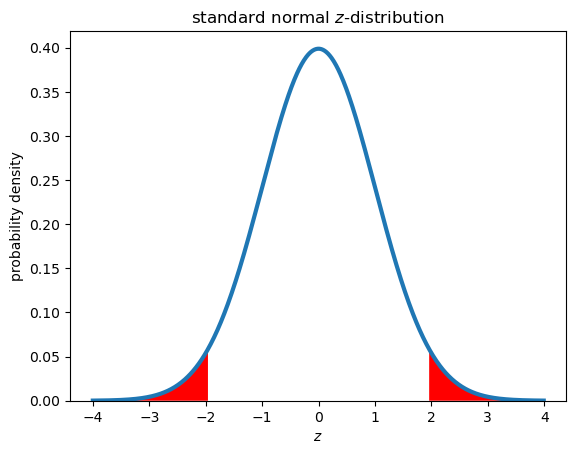
The 1.96 in the equation above is the critical \(z\)-value for a significance level of \(\alpha\) = 0.05, which corresponds to a 100x(1-\(\alpha\)) confidence level.
This number comes from the standard normal distribution shown below, where 95% of the values in this distribution fall between \(z_{0.025} = \) -1.96 and \(z_{0.925} = \) 1.96. The subscripts on the critical \(z\)-values represent the cumulative probability - 97.5% of values fall below 1.96 and 2.5% of values fall below -1.96, with 95% of the values falling between theses critical values. Note that because the distribution is symmetric, \(z_{0.025} = -z_{0.025}\).
We can therefore write the confidence interval in a few different ways:
\(CI_{95\%} = \bar{x} \pm 1.96 \times SE\)
\(CI_{95\%} = \bar{x} \pm z_{crit} \times SE\)
\(CI_{95\%} = \bar{x} \pm z_{0.975} \times SE\)
\(CI_{95\%} = \bar{x} \pm z_{1-\alpha/2} \times SE\)
# significance level
alpha = 0.05
# plot t-distribution
zvalues = np.arange(-4,4,0.01)
zpdf = stats.norm.pdf(zvalues)
plt.figure()
plt.plot(zvalues,zpdf,lw=3)
plt.xlabel('$z$')
plt.ylabel('probability density')
plt.title('standard normal $z$-distribution')
plt.gca().set_ylim(bottom=0)
# plot rejection regions
zcrit = stats.norm.ppf(1-alpha/2)
upperi, = np.where(zvalues>zcrit)
loweri, = np.where(zvalues<-zcrit)
plt.fill_between(zvalues[upperi],zpdf[upperi],facecolor='red')
plt.fill_between(zvalues[loweri],zpdf[loweri],facecolor='red');
Example: fish weight distribution#
The plot below shows 95% confidence intervals for the mean for different subsets that are randomly selected from the main dataset. The default plot shows results from 100 trials (you can think of this as doing 100 trawls) where \(N\) = 10 samples are collected in each trial. The population mean (or true mean) estimated from the larger dataset is shown in blue. This is a fixed parameter and does not change.
The confidence intervals generally encompass the population mean. However, there are some trials where the confidence intervals fail. Also, by making the sample size small (e.g. \(N\) = 3) you can see that the confidence intervals start to encompass negative values, which is not realistic for this data set.
ntrial = 1000
xm = np.nan*np.zeros(ntrial)
xs = np.nan*np.zeros(ntrial)
xci_lower = np.nan*np.zeros(ntrial)
xci_upper = np.nan*np.zeros(ntrial)
ii = (ds['scientific_name'] == 'Engraulis mordax') & (ds['standard_length'] < 1e8)
xmean = np.mean(ds['weight'][ii])
xstd = np.std(ds['weight'][ii],ddof=1)
xSE = xstd/np.sqrt(100)
def plot_confidence_intervals(N, ntrial):
cnt = 0
for i in np.arange(ntrial):
subi = np.random.randint(0, len(ds['weight'][ii]), N)
xm[i] = np.mean(ds['weight'][ii][subi])
xs[i] = np.std(ds['weight'][ii][subi], ddof=1)
(lower,upper) = stats.t.interval(0.95, N-1, loc=xm[i], scale=xs[i]/np.sqrt(N))
xci_lower[i] = lower
xci_upper[i] = upper
#xci_lower[i] = xm[i]-1.96*xs[i]/np.sqrt(N)
#xci_upper[i] = xm[i]+1.96*xs[i]/np.sqrt(N)
if (xmean >= xci_lower[i]) & (xmean < xci_upper[i]):
cnt = cnt + 1
plt.figure(figsize=(5,5))
for j in np.arange(0,ntrial):
if (xmean >= xci_lower[j]) & (xmean < xci_upper[j]):
plt.plot([xci_lower[j], xci_upper[j]], [j,j], 'k-')
else:
plt.plot([xci_lower[j], xci_upper[j]], [j,j], 'r-')
yl = plt.ylim()
plt.plot([xmean,xmean], yl, 'b--')
plt.ylim(yl)
plt.title('95% confidence intervals\nrandom subsets with N = ' + str(N))
plt.xlabel('weight [g]')
plt.ylabel('trial #')
plt.xlim([-10, 50]);
interact(plot_confidence_intervals,
N=widgets.IntSlider(min=5, max=100, step=1, value=10),
ntrial=widgets.IntSlider(min=10, max=200, step=1, value=100));
The visualization above is inspired by a similar visualization by Kristoffer Magnusson at https://rpsychologist.com/d3/ci/. An excerpt from the description on site is worth keeping in mind:
The take home message is that we must accept that our data are noisy and that our results are uncertain. A single “significant” CI or p-value might provide comfort and make for easy conclusions. I hope this visualization shows that instead of drawing conclusions from a single experiment, we should spend our time replication results, honing scientific arguments, polish theories and form narratives, that taken all together provide evidentiary value for our hypothesis. So that we in the end can make substantive claims about the real world.
Common misinterpretation of confidence intervals*:#
“There is a 95% chance that the population mean falls within the interval.”
What is wrong with this statement, and how does it differ from the correct interpretation?
In the case of confidence intervals, we can’t interpret them in this way because the population parameter has a fixed value - it is or it isn’t in the interval
It is the sample mean that has a probability of falling within the confidence intervals, not the true mean or population mean
Confidence intervals treat the parameter as fixed (it has one true value) and the interval as variable (it will change based on the subset of data actually collected).
*Adapted from: http://statsthinking21.org/sampling.html
“The parameter is an unknown constant and no probability statement concerning its value may be made.”
Jerzy Neyman, 1937 Inventor of the confidence interval
Confidence intervals (along with p-values) are examples of frequentist statistics, which rely on a set of hypothetical experiments conducted many, many (technically, infinitely many) times. We need to be careful thinking about how we apply and interpret frequentist statistics in the typical case where we only have samples from one experiment.