Optimization and nonlinear modeling
Contents
1. Optimization and nonlinear modeling#
1.1. Parameter estimation: linear fit#
For linear problems, you can set up a design matrix and use the least squares fit. Examples we have already discussed include:
Linear regression: \(y = mx + b\)
Multiple linear regression: \(y = b_0 + b_1x_1 + b_2x_2\)
Multiple linear regression with interaction term: \(y = b_0 + b_1x_1 + b_2x_2 + b_3x_1x_2\)
Harmonic fit: \(y = a_1 + a_2 \sin(x) + a_3 \cos(x)\)
The problems are all classified as linear, even if the functions do not describe only straight lines, because the unknown coefficients are on the outside the terms in the equation. All of these examples can be expressed in terms of a matrix equation \(\vec{y} = X\vec{c}\).
1.2. Parameter estimation: nonlinear fit#
A simple example of a non-linear model is a model for exponential growth.
Exponential growth: \(y = a_1 e^{a_2 x} = a_1 \exp({a_2 x})\)
In this case, it is not possible to directly solve for \(a_1\) and \(a_2\) with np.linalg.lstsq (the “design matrix” approach that can be used for multivariate regression or harmonic analysis).
1.3. Finding the parameters#
Two ways:
Log Transform -> linear fit
optimization (iterative methods)
The optimization approach minimizes a cost function, \(J\), which is usually the squared sum of errors.
\(J = \sum^N_{i=1} w_i(\hat{y}_i - y_i)^2\)
\(w_i\) is the weight for each data points
\(\hat{y}_i\) is the model estimate,
\(y_i\) is the observation.
\(J\) is sometimes referred to as a chi-square variable since it is a sum of squares.
If the weights \(w_i\) are all equal to 1, then each observation \(y_i\) is weighted the same. In some cases, we may have some uncertainty estimate \(\sigma_i\) for each observation. In that case we may want to give less weight to the data points that have more error, so that \(w_i = 1/\sigma_i^2\).
Goal: minimize J#
import numpy as np
import matplotlib.pyplot as plt
# plot an idealized polynomial cost function for illustrative purposes
p = np.linspace(-4,4)
plt.figure()
plt.plot(p,0.02*(p+4)*(p+1)*(p-1.5)*(p-3.5))
plt.gca().annotate('global minimum',
xy=(-3,-1.2), xycoords='data',
horizontalalignment='center', verticalalignment='top')
plt.gca().annotate('local minimum',
xy=(2.7,-0.55), xycoords='data',
horizontalalignment='center', verticalalignment='top')
plt.xlabel('parameter, $p$')
plt.ylabel('cost function, $J$')
plt.gca().get_xaxis().set_ticks([])
plt.gca().get_yaxis().set_ticks([])
[]
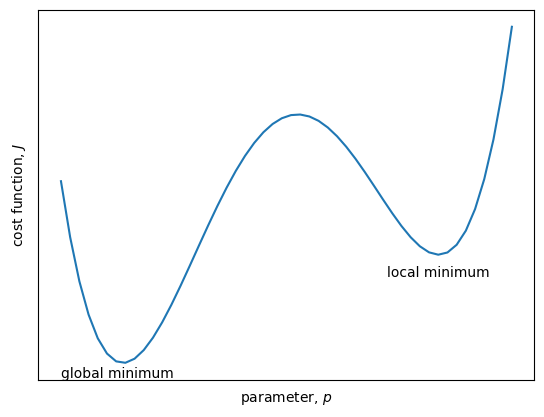
The figure above shows the cost function (\(J\), y-axis) for a model that depends on one parameter(\(p\), x-axis).
The minimum J must occur when:
\(\frac{\partial J}{\partial p } = 0\)
Note that there can be only one global minimum but many local minima. If a cost function is noisy, with many local minima, the parameter optimization problem becomes difficult. Constraining the range of possble parameter values is one way to make the problem easier. There are many algorithms for finding the minimum in \(J\). The best approach depends on the problem and the structure of the cost function.
Optimization with two parameters#
Example: exponential growth#
\(y = a_1 e^{a_2x}\) - modeling exponential growth
This equation means that overall growth rate depends on the population size. For example, if we were trying to model a phytoplankton population, \(P\), then the overall growth rate of the population could be expressed as:
\(\frac{dP}{dt} = \mu P\),
where the constant \(\mu\) is the specific growth rate \([d^{-1}]\). It is related to the doubling time of the population
\(\mu = \frac{\ln(2)}{\text{doubling time}}\).
The analytical solution for the population as a function of time is:
\(P(t) = P_0 e^{\mu t}\)
where \(P_0\) is the initial population at \(t = 0\).
If there are two unknown parameters he cost function can be visualized as a topography in parameter space. Local minima in \(J\) are found in the valleys of the topography. For three dimensions or more, it is harder to visualize the cost function in parameter hyperspace, but the idea is the same.
For two parameters, the optimization problem becomes difficult if the minimum is in a long valley rather than a deep hole. Sometimes this issue can be avoided by scaling the parameters so that their values are of the same order (similar to the approach of standardizing variables in the multiple linear regression problem).
The details of different types of algorithms, and their implementation in Python, can be found at http://www.scipy-lectures.org/advanced/mathematical_optimization/