Principal Component Analysis (PCA) and Empirical Orthogonal Functions (EOFs)
Contents
1. Principal Component Analysis (PCA) and Empirical Orthogonal Functions (EOFs)#
The goal of principal component analysis (PCA) is to efficiently represent variability that is common among multiple variables. One application is to create an “index” that describes how different variables co-vary, or how a single variable co-varies in different places. Empirical orthogonal functions (EOFs) are a very similar type of analysis that involves the same basic steps (often seen in Physical Oceanography or Meteorology literature).
1.1. Visualizing in two dimensions (two variables)#
PCA is easiest to visualize when there are only two variables. The same data can be visualized on different axes if you simply rotate the data into a new coordinate system with new axes.
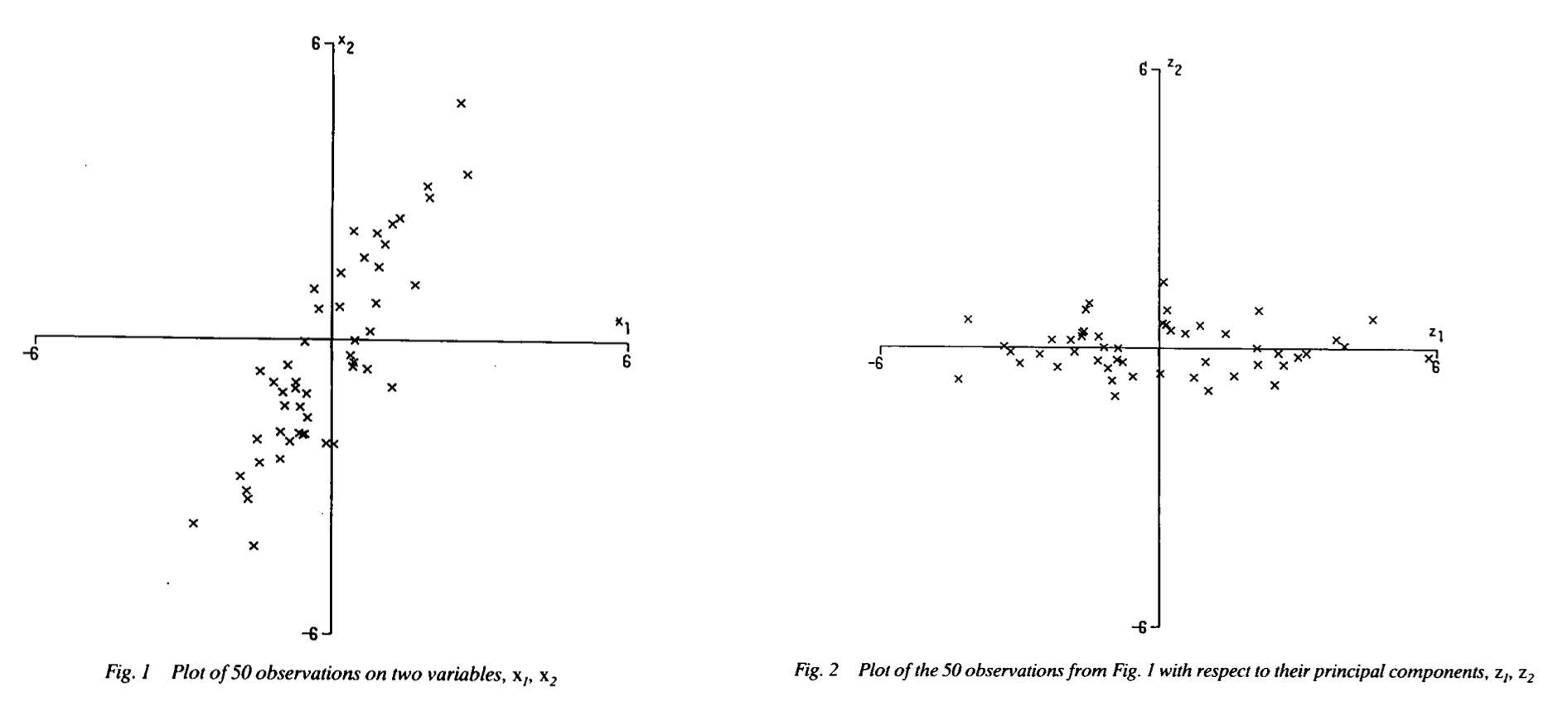
Image source: Joliffe (1990) Weather
In the figure above, the data are rotated into a new coordinate system that maximizes the variance, or spread, in the data along the x-axis (the major axis) and minimizes the variance in the y-axis (the minor axis). This particular type of PCA in two dimensions is often referred to as principal axis analysis. This analysis, which is described in detail below, creates a new coordinate frame that maximizes variability along an axis (PC1) and corresponding orthogonal axis (PC2) where PC1 PC2 are uncorrelated.
A common application of this type of analysis is to rotate data from a East/North coordinate system to natural coordinates primary oriented with the coastline or topography.
Example - Wind vectors#
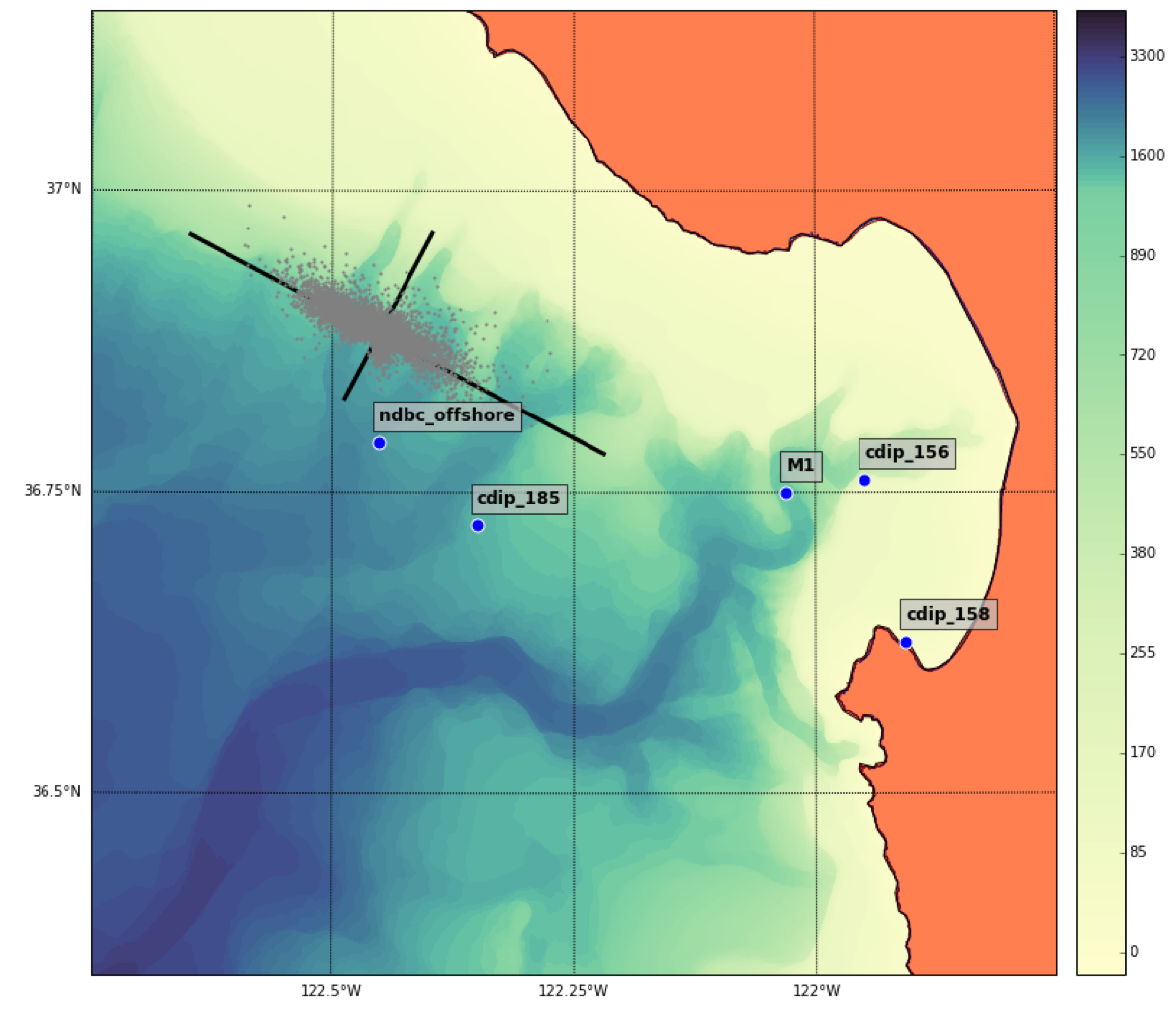
Source: Patrick Daniel, MS 263, Spring 2016
Example from Emery and Thompson - Current meter data#
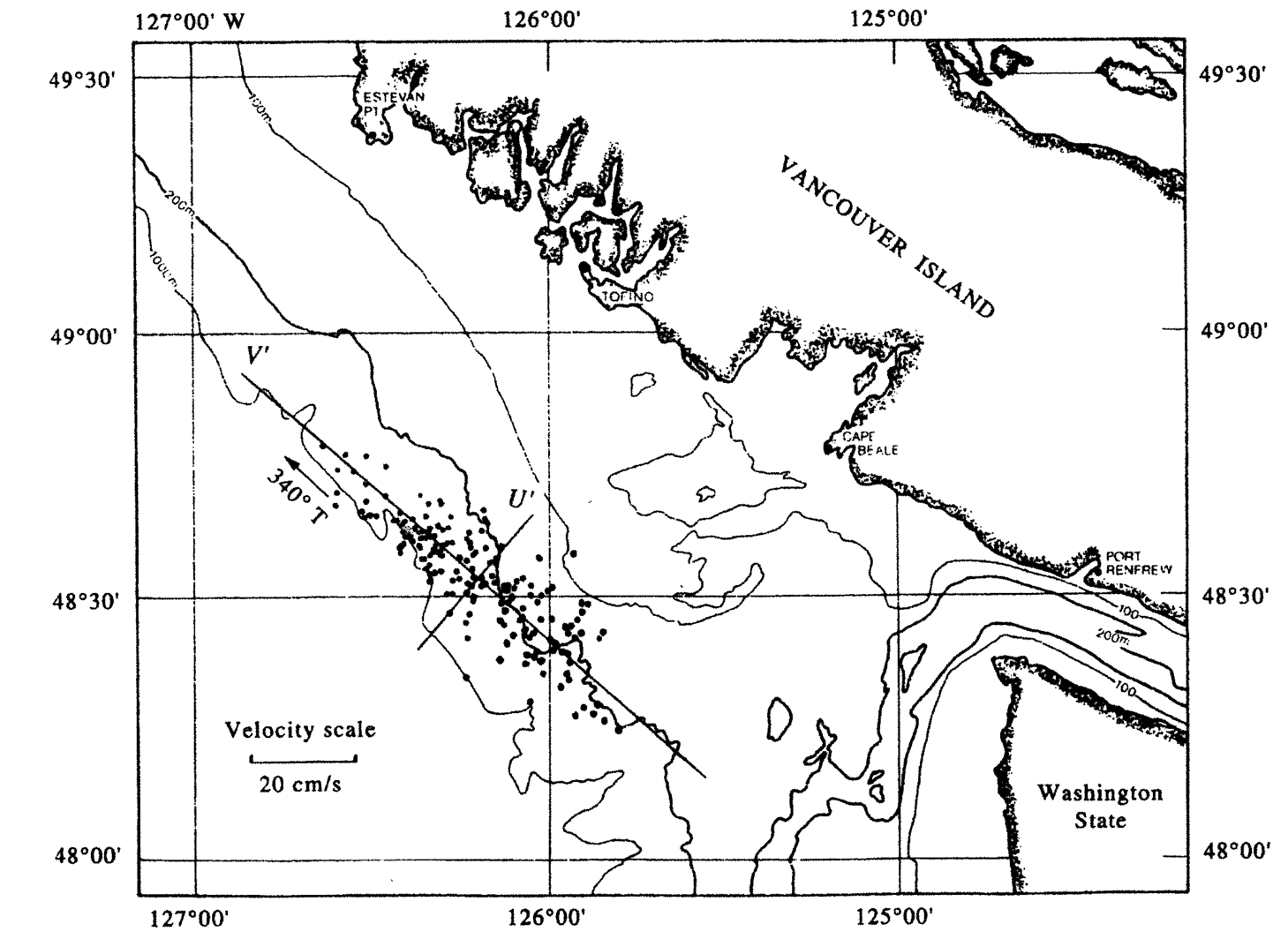
1.2. Principal component analysis: steps#
Create data matrix (size: N x M, N rows and M columns)
standardize if necessary (if data is a combination of different variables)
Form the covariance matrix (M x M)
Extract eigenvalues and eigenvectors from covariance matrix
The eigenvectors are the principal components, the eigenvalues are their magnitudes
Here these steps are decribed for a two dimensional example, focusing on the current meter example above.
1. Data matrix, X#
Creating a data matrix, \(X\)
N rows, M columns
N - number of concurrent samples
M - number of variables
For the current meter example, \(u\) is eastward velocity and \(v\) is northward velocity.
2. Covariance matrix, C (or correlation matrix, R)#
The covariance matrix C has M rows and M columns (M x M). It contains the covariance between all possible combinations of the M different variables that are stored in the different columns of X.
Alternatively, the correlation matrix, R, can also be used. Recall that the correlation between two variables is the covariance scaled by the standard deviation of the variables, \(r_{uv} = \frac{c_{uv}}{s_u s_v}\).
The diagonal elements of the correlation matrix are all equal to 1.
The covariance matrix is generally used when all variables have the same units. Variables or locations with greater variance are weighted higher. The correlation matrix is used when the variables have different units, or if the overall magnitudes do not matter. Use of the correlation matrix standardizes the data so that they are all weighted equally. It is equivalent to transforming the data into z-scores first, and then computing the covariance matrix.
Current meter example: covariance matrix#
For the case of finding the principal component of wind or current meter data, the variables are the eastward component (\(u\)) and the northward component (\(v\)). The covariance matrix has two rows and two columns.
\(c_{uu}\) variance of \(u\)
\(c_{vv}\) variance of \(v\)
\(c_{uv}\) covariance of \(u\) and \(v\)
The values for this example are given in Emery and Thomson,
where units are in \(\frac{cm^2}{s^2}\)
Calculating the covariance matrix can also be done in Python with the numpy.cov() function.
3. Extracting the eigenvalues and eigenvectors from the covariance matrix#
The eigenvectors (contained in the matrix \(V\)) and eigenvalues (contained in the matrix \(\Lambda\)) of the \(C\) matrix are defined by the relationship:
\(V\) = eigenvectors (M x M matrix)
Each column is one eigenvector
\(\Lambda\) = eigenvalues (M x M)
where \(\lambda _1\) - eigenvalue # 1, \(\lambda _2\) - eigenvalue # 2, etc.
4. Physical meaning of the eigenvalues and eigenvectors#
The eigenvectors describe directions in M-dimensional space. These are called the principal components, which define the orientation of new axes for the data. All eigenvectors are orthogonal (or perpendicular, for the 2D case). The vectors that define the axes can be scaled any magnitude, but usually they are scaled to have a value of one (unit vectors).
The eigenvalues describe how each eigenvector is scaled. They describe the variance in the data along each axis defined by the orientations of the eigenvectors.
Back to the current meter example#
To compute the eigenvectors and eigenvalues of a matrix in Python, use:
from scipy import linalg
linalg.eig(C)
For the covariance matrix \(C\) given above,
The columns of the V matrix define the orientation of the new axes (or principal components) in \(u,v\) space. The first column defining PC 1 has a negative slope (\(u\) = 0.771, \(v\) = -0.636) because the variance in the data is primarily oriented in the northwest/southeast axis in \(u,v\) space.
\(\lambda _1\) = 690.6 \(\frac{cm^2}{s^2}\) = variance along PC 1
\(\lambda _2\) = 74.5 \(\frac{cm^2}{s^2}\) = variance along PC 2
Note that there is much more variance along PC 1 (the major axis) than PC 2 (the minor axis). The data have been rotated so that the variance is maximized along PC 1 and minimized along PC 2.
To recover the data in the rotated coordinates,
\(\tau _1 = X V_i\)
\(\tau _1\) = u(0.771) + v(-0.636)
\(\tau _2\) = u(0.636) + v(0.771)
For this example, this would create new variables for alongshore and cross-shore velocity. This is the same data, just rotated into a new set of axes, where alongshore is defined by the axis of maximum variance (the major axis).
Factor loading is another common terminology encountered in EOFs, and refers to the larger spread of data in the first eigenvector (original example v’) than in the second (u’)and thereby quantifying their relative importance and are defined by:
\(A = V \sqrt{\Lambda}\)
Factor loading can be visualized as the length of a PC vectors, whereby PC1 would have a longer vector compared to PC2 (see Emery and Thompson PCA figure above).
1.3. 3-D visualization of principal components#
For three variables, defined by three axes, three principal components are obtained. The first two define a plane in three-dimensional space. These are the two axes that define a a plane where the data would be most spread out if you looked at the data from a perspective perpendicular to the plane.
 [source](http://ordination.okstate.edu/PCA.htm)
[source](http://ordination.okstate.edu/PCA.htm)
For an interactive visualization of PCA in three dimensions, see this link:
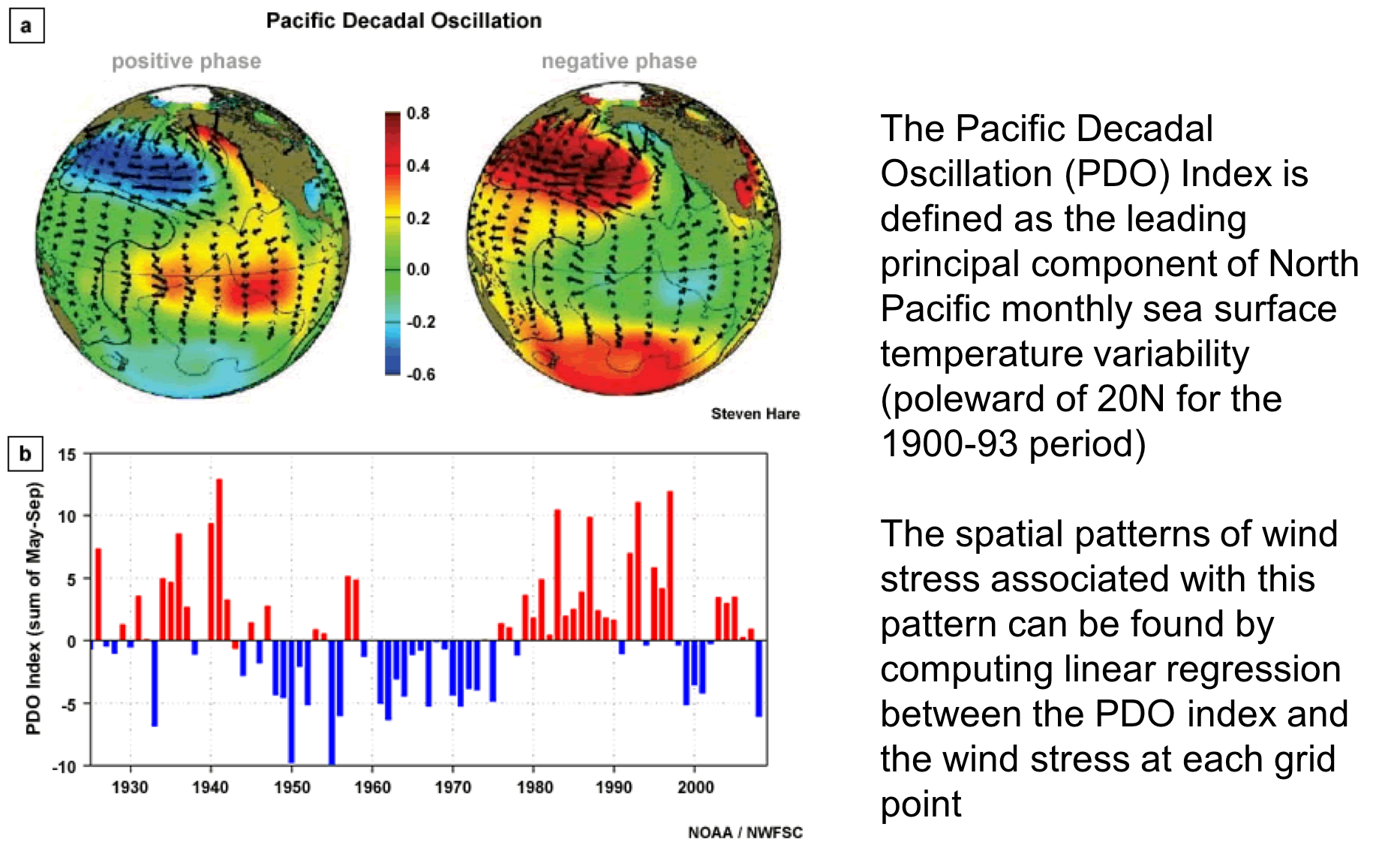
1.4. Example: the Pacific Decadal Oscillation#
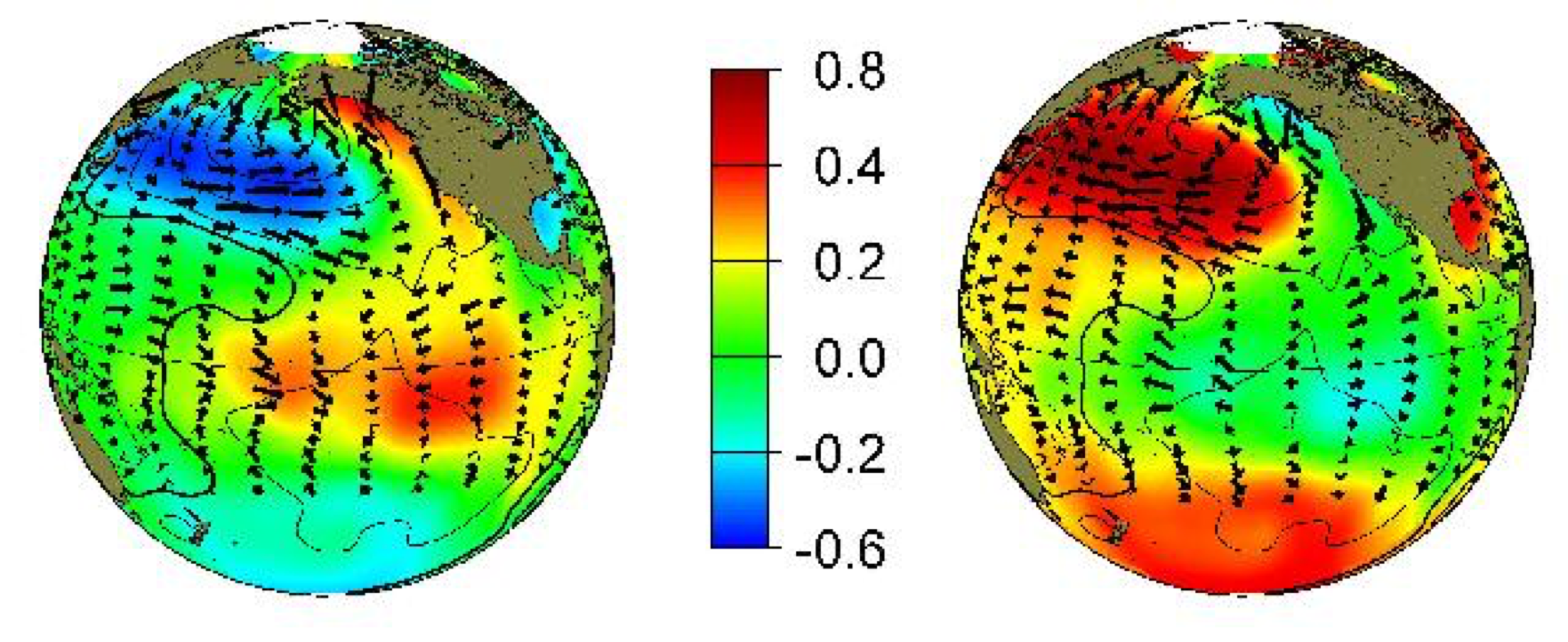
The Pacific Decadal Oscillation (PDO) is defined as the first principal component of SST in the North Pacific. The origin of this index comes from Davis (1976).
This study used binned SST data from 1947-1974 in 82 different sites across the Pacific Ocean.
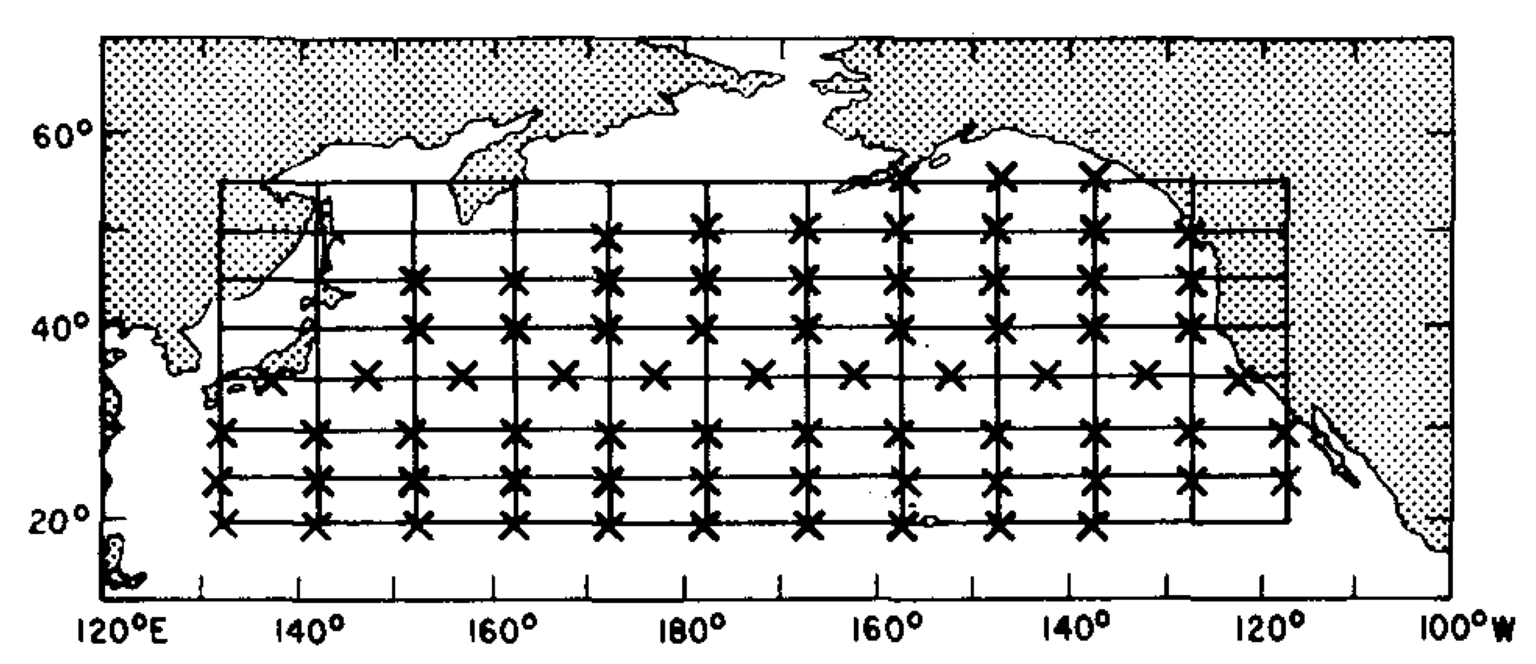
Davis, R.E. (1976) Predictability of sea surface temperature and sea level pressure anomalies over the North Pacific Ocean. J. Phys. Oceanogr., 6, 249-266.
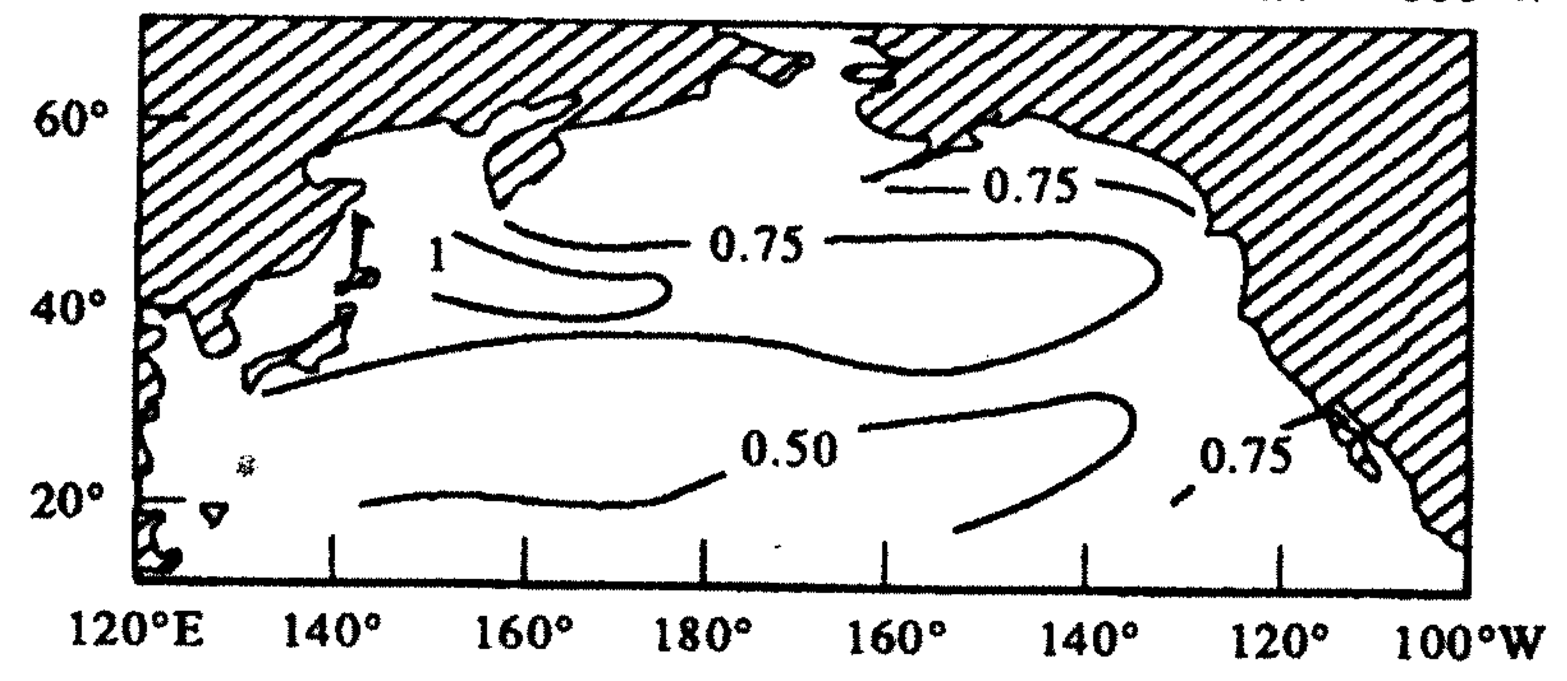
Standard deviation of temperature anomaly [deg C]
Temperature anomaly = temperature – seasonal monthly mean temperature
Data matrix:#
(336 X 82) -> 28 years * 12 month
Create a covariance matrix (what size?)#
(82 x 82)
First principal component/empirical orthogonal function of North Pacific SST#
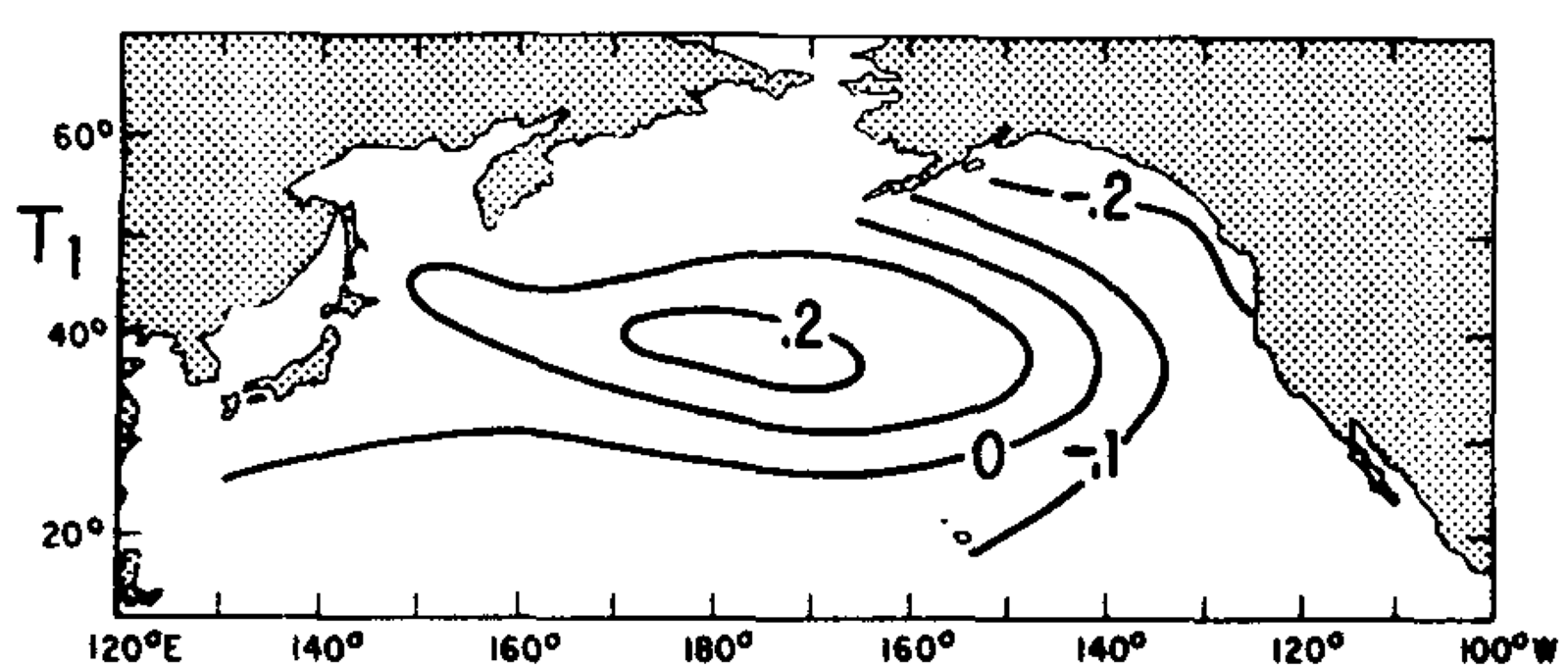
This is the dominant “mode” of temperature variability in the North Pacific, based on how temperature at different locations co-vary together (i.e. the covariance matrix).
This PC is a vector defined by 82 different numbers. It is the first column of an (82 x 82) eigenvector matrix (V). It can be visualized by mapping each value back to its corresponding spatial location.
Other principal components of North Pacific SST#
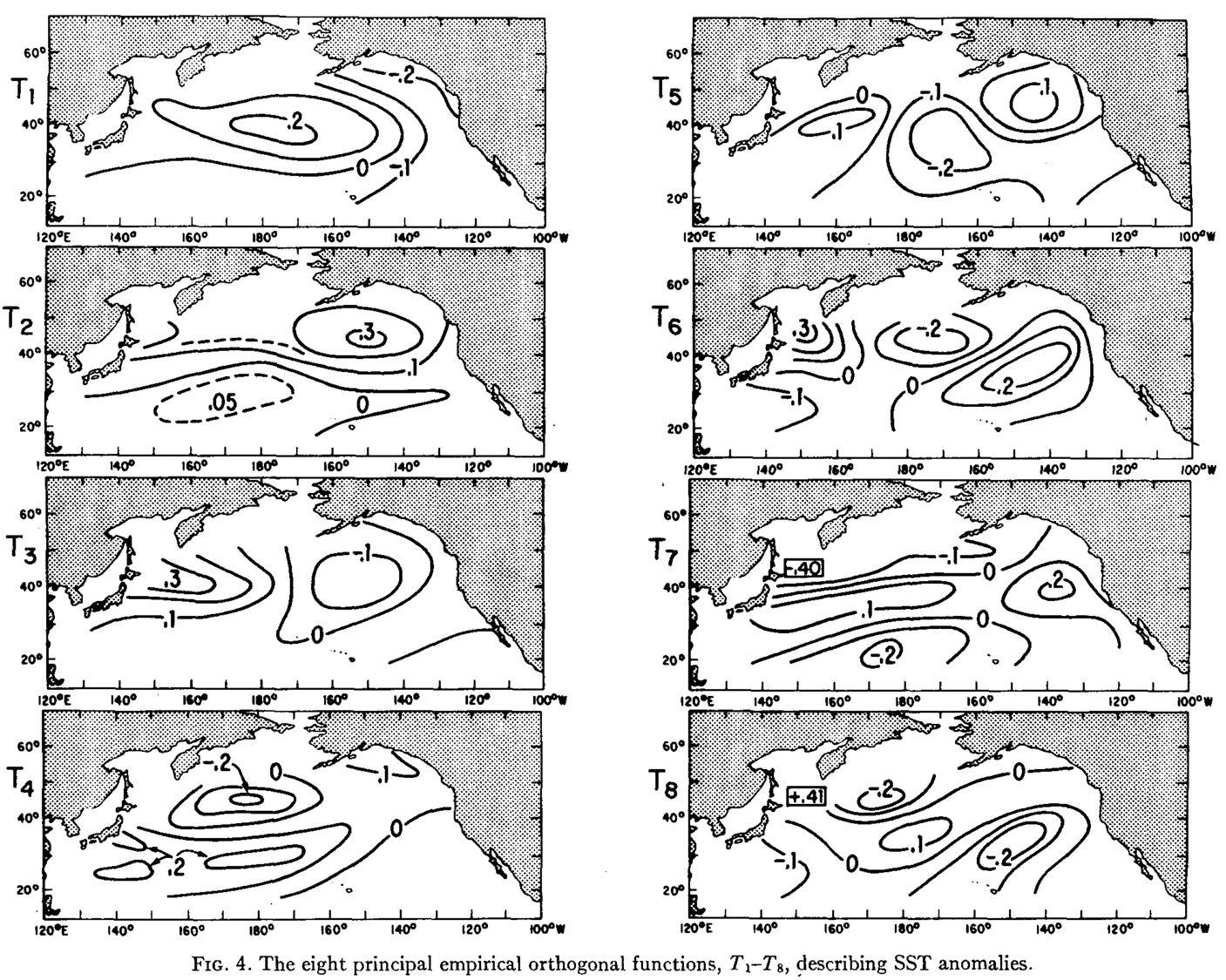
Fraction of Variance that is accounted for by the fist M empirical orthogonal functions#
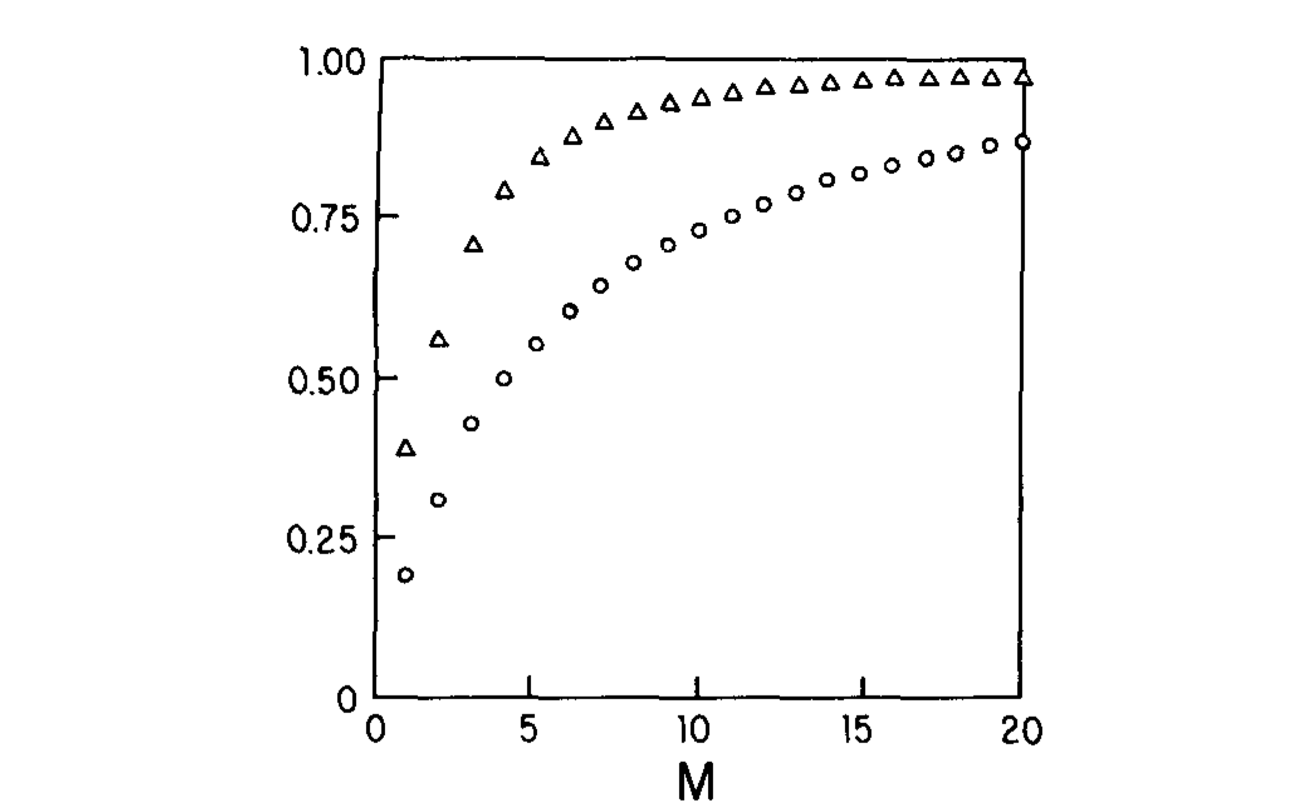
Principal component scores#
The first PC can be used to create an index describing the time variability of the dominant mode. This is the PDO index, which decribes a mode of temperature variability that can be compared with ecosystem parameters (e.g. zooplankton abundance).
PCA assumptions#
Relationships between variables are linear
Mean and variance are sufficient statistics (variables have Gaussian/normal distribution)
Large variances have import dynamics (high signal to noise ration)
The principal components are orthogonal
PCA Issues#
Does not take into account phase lags between correlated variables, can detect “standing” features but not propagating waves. The PDO oscillates back and forth between cool and warm phases like a see-saw, it does not propagate across the Pacific like a wave. If there are wave-like features in the data, PCA will split up the variance between multiple modes, confusing interpration.
Domain dependence: can get a different answer by changing the spatial extent of the data
Shlens, J., A tutorial on principal component analysis: Derivation, discussion and singular value decomposition. https://www.cs.princeton.edu/picasso/mats/PCA-Tutorial-Intuition_jp.pdf
Example:
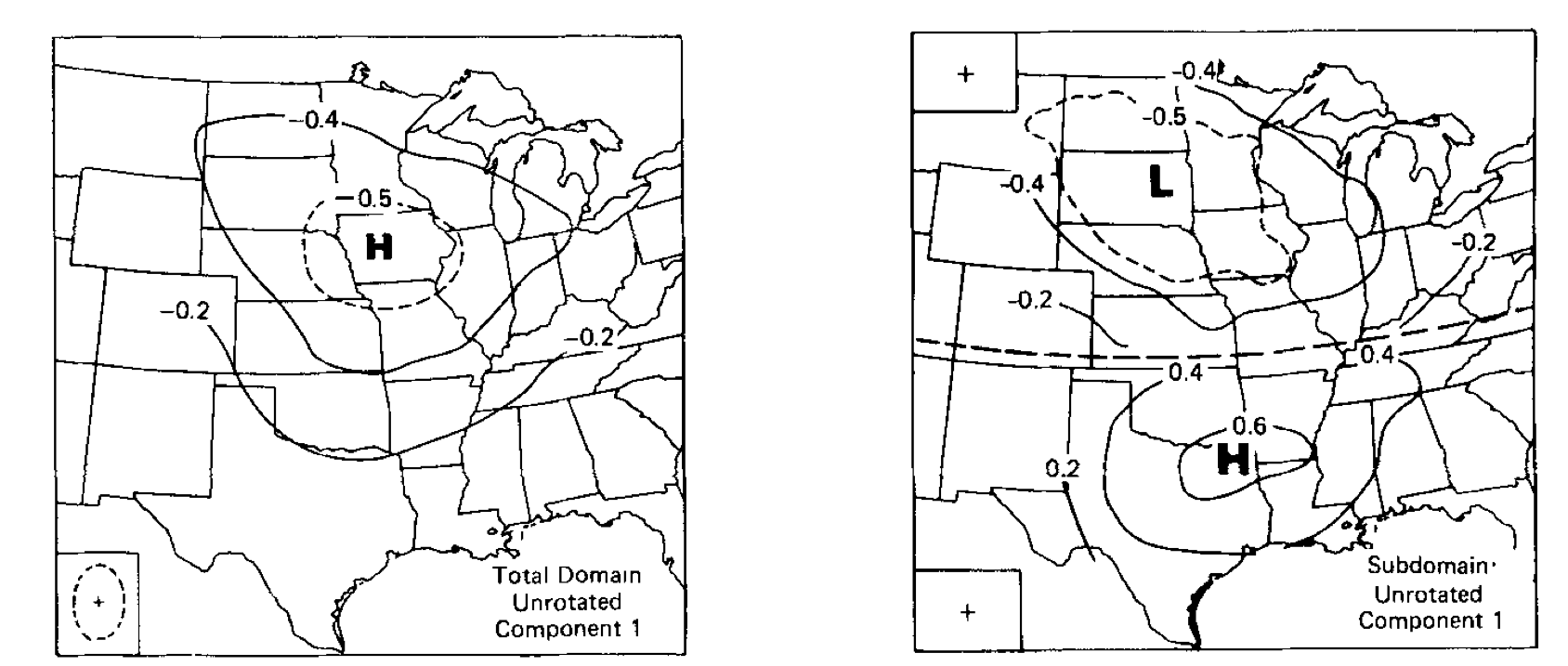
If no dominant pattern exists, PCA will pick out a pattern that may not be robust.